Document dbt Models the easy way with dbt-sugar
Would you like your documentation workflow to look something like this? Now it’s possible with dbt-sugar
 NOTE: This tool is still pretty new and in alpha/beta stage, but we think you can start testing it and helping us making it better along the way.
NOTE: This tool is still pretty new and in alpha/beta stage, but we think you can start testing it and helping us making it better along the way.
- Contribute on GitHub
- Become part of the community by joining our Discord server
If you’re a user of dbt chances are you’re already are on a great path to making your data team successful at iterating and serving analytical value to your business. If you don’t, it’s not too late especially if you don’t have an ELT/ETL workflow that let’s your data people (be it analysts, data engineers or data scientists) only focus on writing a SQL select statement.
If you don’t know what dbt is, no one better than the makers of the tool can speak about it and here are places where you can learn more about the tool, as well as ways in which a growing number of data teams are using it across the world.
Let’s start with some context! However, if you’d like to cut to the chase and learn more about the tool itself you can jump to this section
We <3 Documentation
That’s a fact, good documentation is just a gift from whatever higher-forces of data you believe in. Not just data actually. For example, in my engineering entourage, I often overhear conversations between developers that go something like “Oh my god have you ever used the API from <insert_company> their documentation is SO amazing!”. By the by, dbt is one, Stripe is another.
The reality, though, is we’re all hiding some pain underneath our smiles and proclaimed love for documentation. Writing documentation is often, and quite sadly, an afterthought in the modern fast-paced data world. So is testing by the way but that’s a topic for another time! As a consequence, instead of “I love writing documentation, it’s one of the first things I do” we often hear “Yeah… I’ll document this later, it’s a small thing, I don’t have the time now to go back and forth and update it.”
Why do we skimp so much?
Why do we skimp so much on something we all recognise the value, joy and enablement good and accurate documentation is to us?
My feeling, and one that I’m sure a lot of people share, is that writing documentation and keeping it up to date kinda sucks. It sucks because it’s something else you have to do. It’s not a blocker so you don’t have to do it in order to make your release work. It sucks because, usually, documentation lives “somewhere else”. It sucks because it’s nearly impossible to keep it up to date in a predominantly incremental and iterative workflow (the de facto modus operandi for most data practitioners). Even in an awesome tool like dbt, it’s somewhere else and not automatically kept up to date. That being said, it’s not far at all and dbt offers a great way to serve this documentation as a webpage out of the box so if you use it, you’re already ahead and in a much better place.
Documenting your dbt projects and keeping them consistent is now a fun experience if you use dbt-sugar
What is dbt-sugar?
dbt-sugar is an opinionated CLI tool which helps users of dbt documenting fields and enforcing test coverage on their dbt models. It makes documentation and testing the entitas principalis of data modellers’ every day workflow.
If you attended Coalesce last December, you will have heard my colleague Jeff and I talk about the kind of tools that our team at TripActions developed to make our workflows more efficient and less human-error prone (watch the video Supercharging your data team on dbt’s YouTube channel). One of the tools our amazing data engineer Virginia built is a lot like dbt-sugar –that’s kinda where the inspiration for it comes from and I coincidentally happen to maintain with Virginia in our downtime under the bitpicky open source organisation umbrella I started a few months ago.
Ok show me what it does already!
In short, dbt-sugar will guide you through documenting a dbt model in your dbt project. You simply call the dbt-sugar doc task, point it to your model and voila you get an experience such as the one below:
You go from an empty schema.yml to a nicely populated one like this
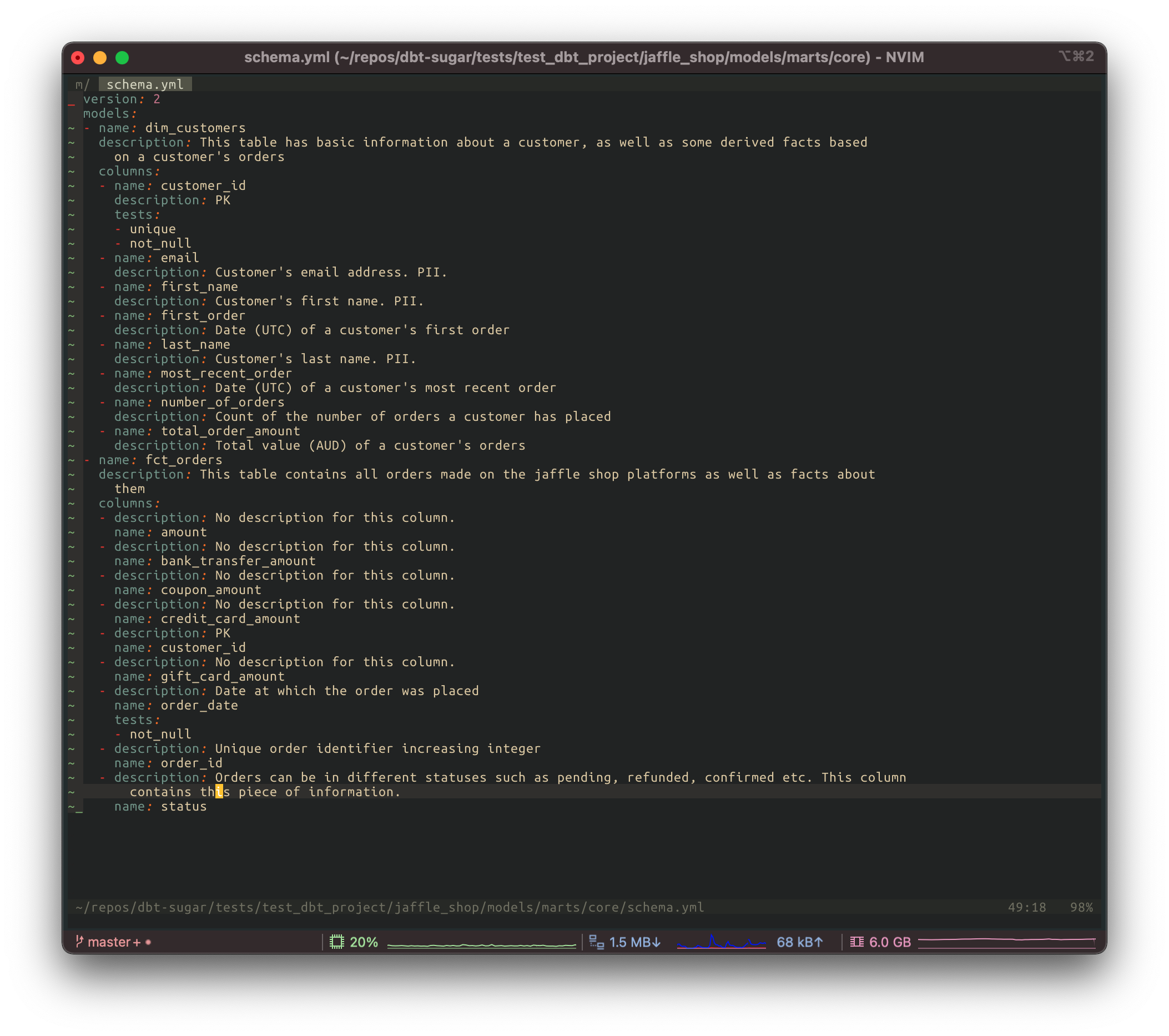
But WAIT, you only wrote documentation for the order_date column, how do you get the order_id column to be magically filled in??
Good catch! Cool isn’t it? The main advantage of using dbt-sugar is that it knows about the columns you already documented in all of your other models and it populates it for you!
It runs the tests?
Yep! No point adding a test if it fails already right? This would lead you to deploy your model, only to have the model fail its assumptions on the next run. When you ask for a test to be added on a column, dbt-sugar will run it for you. If it passes, great it gets added, if it fails you get a message that one of your assumptions isn’t met and you can fix it before it ends up in the code base and no-one will ever know!
 In this case, the unique test failed so it was not added and
In this case, the unique test failed so it was not added and dbt-sugar told you about this so you don’t have any surprises.
What else does dbt-sugar do for you?
- Allows you to document undocumented columns
- Allows you to re-document already documented columns and add missing tests or tags
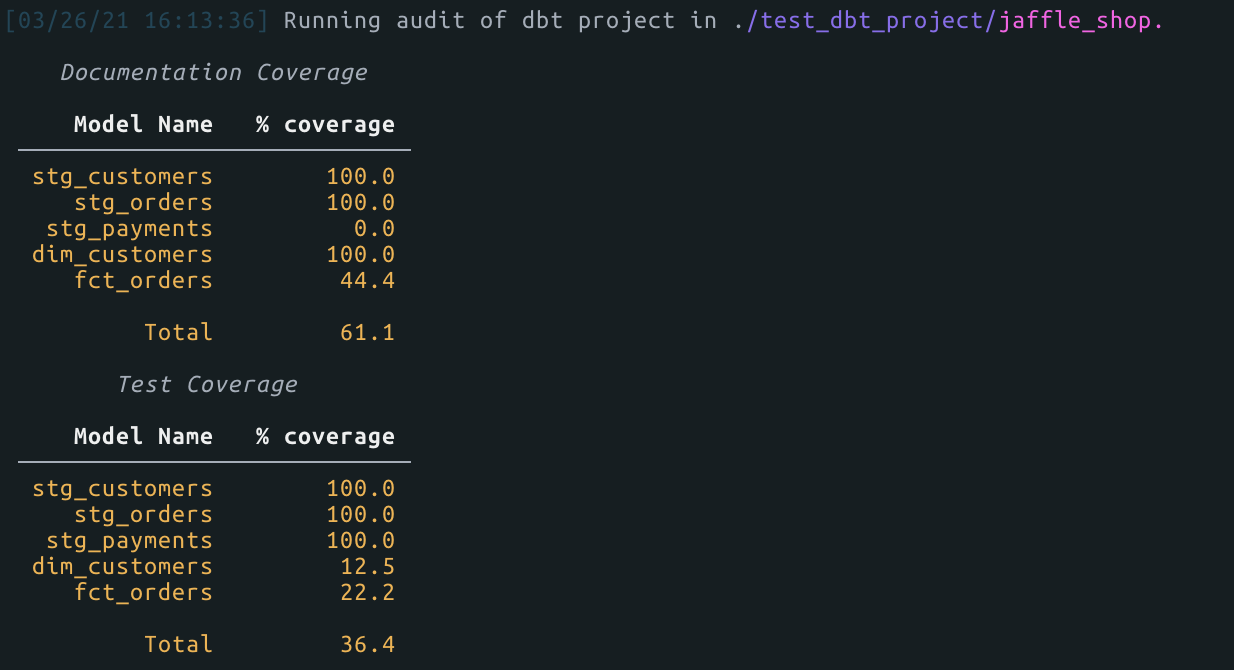
- Gives you a nice audit summary. For example if you do
dbt-sugar auditon your dbt model you will get something that looks like this:
Want to start using it?
- dbt-sugar is currently able to talk to Snowflake and Postgres databases and is extensible to work with most other major databases (feel free to get inlvoved if you have access to such other databases).
- dbt-sugar is really easy to configure as long as your dbt
profiles.ymlis set up and you have a dbt project running. All you need to do is add a minimal set of config options, which we callsyrup(cos it’s sweet) that looks like this:
defaults:
syrup: syrup_1
target: dev
syrups:
- name: syrup_1
dbt_projects:
- name: dbt_sugar_test
path: "./tests/test_dbt_project/dbt_sugar_test"
excluded_tables:
- table_a
Check out the tool’s documentation to get you setup and configured.
Want to get involved in the development?
- Check out our repository, we also tell you how you can start contributing
- Report bugs or discuss features in a GitHub issue or check our what’s currently in the works in our project boards
- Want to talk to a human, having some issues that you can’t troubleshoot yourself, want to be part of the community? Join bitpicky’s Discord server